Scaling CSV creation in Django
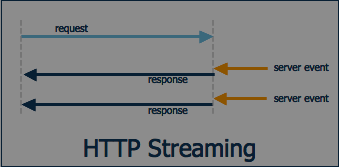
Table of contents

Many of you might have come across the functionality to export data to a CSV/JSON in your day-to-day applications. It is a very common utility, and it’s a better practice to handle the complex logic on the Backend and render the data as desired to the client.
It’s straightforward to build when the dataset to be exported is small and static, i.e. you need to render the data from one source to another.
Scaling for larger data-sets
The complexity increases significantly when dealing with a large dataset especially when it needs to be processed on the fly to generate the final output.
For eg, passing your raw data to an ML algorithm/ or validating it against some predefined rules to get some insights. These algorithms may change with time or are dependent on some real-time attributes, making it impossible to pre-compute and serve saved data.
I faced this situation in one of my projects. The project was about processing health insurance claims and involved a huge amount of data (related to Patient Claims). The dataset includes a large number of attributes (almost 200) in our database models with millions of rows.
What was the product requirement?
Usually, the application dealt with one claim in a request when the User was working with the frontend.
But then the product team asked us to build a feature that would enable a user to export the output as a CSV. The CSV could potentially include hundreds of thousands of records. The CSV had to be generated once the user requested it through a download button on the application frontend. Generating a large CSV in response to an API request is bound to run into several issues.
Issues we faced during development
One of the issues was naturally the memory consumption on the backend and database server in handling even one of these requests. And moreover, loading the dataset and doing computations in memory wasn’t going to scale well.
Additionally, HTTP requests have a default timeout limit of 60 seconds. Yes, increasing the limit on Nginx/ Gunicorn is an option, but that isn’t an elegant solution and doesn’t solve the memory consumption of the backend servers, and may also result in hanging connections.
There were two main approaches to consider:
Go Async:

The server stores the request to generate the CSV by the user in a message broker like Redis or Rabbitmq, and a Celery worker actually performs the task in the background.
Here we dedicated a server (which we can enable only for a specific time during the day) for this purpose. Once we had the final output in the desired format, we shared a relevant link to the file with the user.
This will be an ideal solution if you’re dealing with audit logs/ secondary data, which might not be an immediate need from a business perspective.
But if the requirement states you to render the response immediately, which was our use case as our data is time-critical, I had to choose an alternative approach.
Streaming the response in real-time:
Streaming HTTP Response not only helps in avoiding in-memory data caching but also reduces the <a href="https://en.wikipedia.org/wiki/Time_to_first_byte#:~:text=Time%20to%20first%20byte%20(TTFB,received%20by%20the%20client's%20browser." target="_blank" style="color:#0057FF; text-decoration:none;">TTFB</a>(Time to First Byte). This usually happens when we download movies, some static file, etc.
Our Implementation:
1. As our dataset was huge (at least a few hundred MBs), we needed to ensure that fetching the data from the database didn’t spike memory consumption on the backend server as we continued querying and processing the raw data.
Solution: We used Iterators (like Generators in Python) to process and fetch the data incrementally that do not allocate memory to all the results simultaneously.
2. The huge dataset could also drag the database server if all data is fetched at once.
Solution: To avoid load on the database server, we used pagination and kept querying the database in batches.
Here’s a sample code that fetches user data in batches using Python’s Generator.
3. Few data points were a bit intensive to calculate (and were dependent on static data points), so we invested our time on the feasibility of pre-processing data and saving it in the database, thus avoiding an intensive task at run time.
A classic example of this would be a banking application, which provides User’s spending on various sectors (Health, Entertainment, Fuel, etc.). Here if all the transactions are pre-populated with a category to which it belongs, it makes the calculation quite simpler than evaluating the category for each transaction at run-time.
4. We scaled up our servers just a little and through the measures above, we were able to stream a data request of 4000 rows in a few seconds. But the response time increased as the data under consideration increased and response time took 4–5 minutes if a user requested a large number of records(50k rows).
Solution: We limited the number of records that a user can request at a time for run-time delivery, and the Async approach otherwise.
Even though we still had to scale our servers and put a few restrictions, the implementation served our goals for the time being and gave us time to look for better solutions. The different approaches we experimented with along the way gave us a clearer understanding of modern scaling techniques and their particular use-cases.

Future Iterations
We did a detailed benchmarking of all the tasks to identify exact functions/logic that was more time-consuming and required performance-related optimizations. From the data collected, we were able to plan the next set of updates to our system to scale it further. These included:
1. Database Architecture: Avoiding over-normalization of database models
2. Database query optimization, proper Indexing
Performance and Scaling are never-ending, it depends a lot on the kind of business problems you are solving and expectations from the product team. It is a continuous, iterative process.
At Default we have a thriving Django practice, working across large and complex databases solving challenges of scale. We are always looking for new team members to join us.
Thanks to Rishabh Jain.
Many of you might have come across the functionality to export data to a CSV/JSON in your day-to-day applications. It is a very common utility, and it’s a better practice to handle the complex logic on the Backend and render the data as desired to the client.
It’s straightforward to build when the dataset to be exported is small and static, i.e. you need to render the data from one source to another.
Scaling for larger data-sets
The complexity increases significantly when dealing with a large dataset especially when it needs to be processed on the fly to generate the final output.
For eg, passing your raw data to an ML algorithm/ or validating it against some predefined rules to get some insights. These algorithms may change with time or are dependent on some real-time attributes, making it impossible to pre-compute and serve saved data.
I faced this situation in one of my projects. The project was about processing health insurance claims and involved a huge amount of data (related to Patient Claims). The dataset includes a large number of attributes (almost 200) in our database models with millions of rows.
What was the product requirement?
Usually, the application dealt with one claim in a request when the User was working with the frontend.
But then the product team asked us to build a feature that would enable a user to export the output as a CSV. The CSV could potentially include hundreds of thousands of records. The CSV had to be generated once the user requested it through a download button on the application frontend. Generating a large CSV in response to an API request is bound to run into several issues.
Issues we faced during development
One of the issues was naturally the memory consumption on the backend and database server in handling even one of these requests. And moreover, loading the dataset and doing computations in memory wasn’t going to scale well.
Additionally, HTTP requests have a default timeout limit of 60 seconds. Yes, increasing the limit on Nginx/ Gunicorn is an option, but that isn’t an elegant solution and doesn’t solve the memory consumption of the backend servers, and may also result in hanging connections.
There were two main approaches to consider:
Go Async:
The server stores the request to generate the CSV by the user in a message broker like Redis or Rabbitmq, and a Celery worker actually performs the task in the background.
Here we dedicated a server (which we can enable only for a specific time during the day) for this purpose. Once we had the final output in the desired format, we shared a relevant link to the file with the user.
This will be an ideal solution if you’re dealing with audit logs/ secondary data, which might not be an immediate need from a business perspective.
But if the requirement states you to render the response immediately, which was our use case as our data is time-critical, I had to choose an alternative approach.
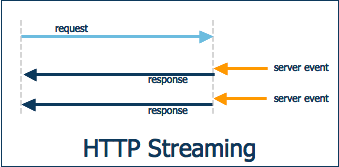
Streaming the response in real-time:
Streaming HTTP Response not only helps in avoiding in-memory data caching but also reduces the <a href="https://en.wikipedia.org/wiki/Time_to_first_byte#:~:text=Time%20to%20first%20byte%20(TTFB,received%20by%20the%20client's%20browser." target="_blank" style="color:#0057FF; text-decoration:none;">TTFB</a>(Time to First Byte). This usually happens when we download movies, some static file, etc.
Our Implementation:
1. As our dataset was huge (at least a few hundred MBs), we needed to ensure that fetching the data from the database didn’t spike memory consumption on the backend server as we continued querying and processing the raw data.
Solution: We used Iterators (like Generators in Python) to process and fetch the data incrementally that do not allocate memory to all the results simultaneously.
2. The huge dataset could also drag the database server if all data is fetched at once.
Solution: To avoid load on the database server, we used pagination and kept querying the database in batches.
Here’s a sample code that fetches user data in batches using Python’s Generator.
3. Few data points were a bit intensive to calculate (and were dependent on static data points), so we invested our time on the feasibility of pre-processing data and saving it in the database, thus avoiding an intensive task at run time.
A classic example of this would be a banking application, which provides User’s spending on various sectors (Health, Entertainment, Fuel, etc.). Here if all the transactions are pre-populated with a category to which it belongs, it makes the calculation quite simpler than evaluating the category for each transaction at run-time.
4. We scaled up our servers just a little and through the measures above, we were able to stream a data request of 4000 rows in a few seconds. But the response time increased as the data under consideration increased and response time took 4–5 minutes if a user requested a large number of records(50k rows).
Solution: We limited the number of records that a user can request at a time for run-time delivery, and the Async approach otherwise.
Even though we still had to scale our servers and put a few restrictions, the implementation served our goals for the time being and gave us time to look for better solutions. The different approaches we experimented with along the way gave us a clearer understanding of modern scaling techniques and their particular use-cases.
Future Iterations
We did a detailed benchmarking of all the tasks to identify exact functions/logic that was more time-consuming and required performance-related optimizations. From the data collected, we were able to plan the next set of updates to our system to scale it further. These included:
1. Database Architecture: Avoiding over-normalization of database models
2. Database query optimization, proper Indexing
Performance and Scaling are never-ending, it depends a lot on the kind of business problems you are solving and expectations from the product team. It is a continuous, iterative process.
At Default we have a thriving Django practice, working across large and complex databases solving challenges of scale. We are always looking for new team members to join us.
Thanks to Rishabh Jain.
Give your product vision the talent it deserves
building your dream engineering team.



.webp)

